8. Dataanalyse med Pandas#
|
Kapitlet bruker følgende datafiler: norge-rundt.csv oda-master-thesis.csv |
En av de vanligste utvidelsene vi bruker når vi jobber med dataanalyse av digitalisert og digitalt datamateriale er Pandas. På mange måter kan det å bruke Pandas sammenlignes med å det å jobbe med datasett i Excel fordi man jobber med datasett i tabellform. Pandas gir deg et arsenal av funksjoner og moduler som man kan bruke og i dette kapitlet vil vi gå gjennom noen av de vanligste. Data vi bruker i dette kapitlet er produsert av NRK, og er metadata om innslag fra TV-programmet Norge rundt. Filen er publisert på Felles datakatalog[1].
Siden dette kapitlet vil importere og eksportere filer er det viktig å nevne noe som er selvsagt men som aldri kan bli sagt ofte nok: Det er viktig å gi filene beskrivende navn. Da er det enklere å forstå innholdet i filen uten å måtte åpne den.
Introduksjon til Pandas og DataFrames#
Pandas er et funksjonsbibliotek (“library”) for å behandle vilkårlig kompliserte tabelldata. Pandas tilbyr verktøy for å:
lese inn data fra filer i utallige formater
analysere og visualisere dataene med hjelp av Python
trekke ut relevante deler fra disse dataene
eksportere data til utallige filformater.
For å kunne bruke Pandas i Python og Jupyter Notebooks må vi først importere den.
as pd gir oss en snarvei, dvs. at funksjoner, metoder og attributer kan hentes fra Pandas ved å skrive
pd istedenfor pandas.
1import pandas as pd
Hoveddatastrukturen i Pandas er en dataframe. Dette er en tabellstruktur med rader, kolonner og celler. Data kan leses inn i en Pandas-dataframe fra mange ulike datakilder. En typisk fremgangsmåte er å hente inn data fra en CSV-fil ved å skrive read_csv()- funksjonen inn i en nyopprettet dataframe (df = ).
1df = pd.read_csv('data/norge-rundt.csv', sep = ';')
pd.read_csv() innebærer at vi bruker Pandas-funksjonen read_csv() for å lese inn en csv-fil.
Tilsvarende funksjoner finnes også for å lese andre filfornater. Funksjonen har mange parametre.
Den første parameteren er adressen, eller stien til CSV-filen. En annen mye brukt parameter er
sep, som spesifiserer hvilket skilletegn som brukes i CSV-filen. Standardverdien, som brukes hvis
sep utelates, er komma. I eksemplet her brukes ; som skilletegn.
⚠️ Merk! Å lese inn en fil betyr at inneholdet i filen trekkes ut. Selve filen forblir det samme uansett hva du gjør i Jupyter Notebooks. For å eksportere det du har gjort til en ny fil må du ta i bruk en annen funksjon som vi kommer tilbake til senere i dette kapitlet når det blir aktuelt.
Du kan laste ned CSV-filen øverst i dette kapitlet. Men hvor du lagrer den er avhengig av hvilken adresse du oppgir i adresse-paramteret .read_csv()
Hvis filen finnes i samme mappe som
notebook’en, trenger vi kun skrive filnavnet. Det vil si at det er lettest for deg å ha både notebook og filer du henter inn data fra i samme mappe.
✍️ Oppgave: Last ned CSV-filen og lagre den i samme mappe som du har dine notebook’er i. Importer Pandas slik det er vist i cellene over i din egen notebook, og les inn CSV-filen.
Grunnleggende informasjon om en dataframe#
Data som er hentet inn fra CSV-filen med metoden read_csv() er lagt inn i en variabel med navn
df. Bruk av variabelnavnet df er en konvensjon når man henviser til en Pandas Dataframe.
Teknisk sett kan man bruke hvilket lovlig variabelnavn som helst (a, b, jens, osv.).
Har man flere variabler av typen “Dataframe” i programmet, må man så klart ha forskjellige navn.
df1, df2 osv. kan brukes, men også andre navn som går på rollen kan brukes.
Hvis vi har en dataframe med tittelinformasjon og en annen om fofatterinformasjon,
vil kanskje hhv. df_titler og df_forfattere funke.
Datatype#
Som vi har vist til i kapittel Variabler, har alle Python-variabler en datatype.
Datatyper kan være enkle: en tekststreng (str), et heltall (int) eller et flyttall (float). Datatyper kan også være
flerverdivariabler slik som list og tuple, eller mer kompliserte, slik som
et xml-tre, lxml.etree (etree tilgjengelig fra pakken lxml).
Bruk av pythons
type()-funksjon på variabelen df avlører at den er av typen pandas.core.frame.DataFrame.
1type(df)
pandas.core.frame.DataFrame
Omfang/kompleksitet#
Omfanget og kompleksiteten til dataene i dataframen uttrykkes ved hvor mange rader og kolonner
som finnes i dataframe’n. .shape-attributtet til en dataframe kan brukes for å finne
dette. Dataframe om Norge Rundt-innslag består av 10219 rader og 32 kolonner.
1df.shape
(10219, 32)
Vi kan også få et overblikk over datasettet som en dataframe:
1df
| aar | video_url | kommune | tittel | tema | hva_er_spesielt | folelse | antrekk | type_bygg_og_industri | type_historisk | ... | tema_kjop_og_salg | type_landbruk_og_fiske | offentlige_tjenester_og_veldedighet | hovedperson1_kjonn | hovedperson2_kjonn | hovedperson3_kjonn | hovedperson1_alder | hovedperson2_alder | hovedperson3_alder | tema_politikk_og_media | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Bergen | Rypejakt | Natur og friluftsliv | NaN | NaN | Caps | NaN | NaN | ... | NaN | NaN | NaN | Mann | Mann | NaN | 10 til 15 | 40 til 50 | NaN | NaN |
| 1 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Sirdal | Kraftutbygging | Bygg og industri | NaN | NaN | Hjelm | Anlegg, Kraftproduksjon | NaN | ... | NaN | NaN | NaN | Mann | NaN | NaN | 40 til 50 | NaN | NaN | NaN |
| 2 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Øksnes | Fraflyttingstilskudd | Politikk | NaN | NaN | Caps, Slips | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | Distriktspolitikk, Samferdselspolitikk |
| 3 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Orkdal | Trønderlån | Kunst og Håndverk | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | Kvinne | Kvinne | NaN | 40 til 50 | 40 til 50 | NaN | NaN |
| 4 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Finnøy | Dyrking av tomater | Landbruk og fiske | NaN | NaN | NaN | NaN | NaN | ... | NaN | Grønnsaker og urter, Tomat | NaN | Mann | Mann | NaN | 30 til 40 | 40 til 50 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 10214 | 2016 | https://tv.nrk.no/serie/norge-rundt/DVNR040025... | Sund | Campingliv (mellomstikk) | Natur og friluftsliv | Livsstil | Ler | NaN | NaN | NaN | ... | NaN | NaN | NaN | Mann | Kvinne | Mann | 50 til 60 | 60 til 70 | 50 til 60 | NaN |
| 10215 | 2016 | https://tv.nrk.no/serie/norge-rundt/DVNR040025... | Porsgrunn | Louie the Skipper | Natur og friluftsliv | Sære vaner | Ler | Caps | NaN | NaN | ... | NaN | NaN | NaN | Mann | Kvinne | Kvinne | 20 til 30 | 30 til 40 | 40 til 50 | NaN |
| 10216 | 2016 | https://tv.nrk.no/serie/norge-rundt/DVNR040025... | Lyngdal | Paulsens hotell | Ukategoriserbart | Personlighet | NaN | Hatt | NaN | NaN | ... | NaN | NaN | NaN | Mann | Mann | Mann | 40 til 50 | 40 til 50 | 60 til 70 | NaN |
| 10217 | 2016 | https://tv.nrk.no/serie/norge-rundt/DVNR040025... | Stjørdal | Dugnadsgjengen Stjørdal museum Værnes | Offentlige tjenester og veldedighet | Livsvisdom | Elsker | Caps, Kjeledress | NaN | NaN | ... | NaN | NaN | Dugnad | Mann | Mann | Kvinne | 60 til 70 | 70 til 80 | 60 til 70 | NaN |
| 10218 | 2016 | https://tv.nrk.no/serie/norge-rundt/DVNR040025... | Hå | Gitarmuseum | Kunst og Håndverk | Livsstil | Wow | NaN | NaN | NaN | ... | NaN | NaN | NaN | Mann | Mann | NaN | 50 til 60 | 30 til 40 | NaN | NaN |
10219 rows × 32 columns
Her ser vi at det har både kolonner og rader. Og vi ser også at de cellene som ikke har en verdi er merket med “NaN”.
Kolonner (“variabler”)#
Enten datasettet handler om salgstall eller instagram-poster blir radene som regel “enheter” (individer, steder, varer), og kolonnene variabler (pris, lønn, temperatur, osv.).
Hver kolonne i en dataframe har en datatype. Metoden .info() kan brukes for å vise informasjon om kolonnene i en dataframe. Dtype viser datatypen av kolonnen.
object tilsvarer str i Python, dvs. tekststrenger
int64 tilsvarer int, dvs. heltall
float64 tilsvarer float, dvs. desimaltall.
Metoden viser også hvor mange av radene i kolonnen som har en verdi. F.eks. alle 10 219 rader i aar-kolonnen har en verdi (ikke er tomme), mens kun 4 882 rader i hva_er_spesielt-kolonnen har en verdi.
1df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10219 entries, 0 to 10218
Data columns (total 32 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 aar 10219 non-null int64
1 video_url 10219 non-null object
2 kommune 10219 non-null object
3 tittel 10219 non-null object
4 tema 10219 non-null object
5 hva_er_spesielt 4882 non-null object
6 folelse 2580 non-null object
7 antrekk 5722 non-null object
8 type_bygg_og_industri 279 non-null object
9 type_historisk 510 non-null object
10 type_natur_og_idrett 0 non-null float64
11 type_kunst_og_haandverk 1794 non-null object
12 type_idrett_og_fysisk_aktivitet 614 non-null object
13 tema_samlere_entusiaster_og_oppfinnere 634 non-null object
14 tema_vitenskap 0 non-null float64
15 relasjoner 745 non-null object
16 type_musikere 576 non-null object
17 type_mat 325 non-null object
18 type_dyr 818 non-null object
19 antall_menn 9013 non-null float64
20 antall_kvinner 6898 non-null float64
21 tema_natur_og_friluftsliv 1109 non-null object
22 tema_kjop_og_salg 231 non-null object
23 type_landbruk_og_fiske 420 non-null object
24 offentlige_tjenester_og_veldedighet 881 non-null object
25 hovedperson1_kjonn 9371 non-null object
26 hovedperson2_kjonn 5774 non-null object
27 hovedperson3_kjonn 3004 non-null object
28 hovedperson1_alder 9368 non-null object
29 hovedperson2_alder 5758 non-null object
30 hovedperson3_alder 2998 non-null object
31 tema_politikk_og_media 145 non-null object
dtypes: float64(4), int64(1), object(27)
memory usage: 2.5+ MB
Vi bruker videre columns-attributtet for å liste kolonnenavnene (om de ikke har navn, blir det automatisk genererte ordenstall). Se også bruken av disse som overskrifter.
1df.columns
Index(['aar', 'video_url', 'kommune', 'tittel', 'tema', 'hva_er_spesielt',
'folelse', 'antrekk', 'type_bygg_og_industri', 'type_historisk',
'type_natur_og_idrett', 'type_kunst_og_haandverk',
'type_idrett_og_fysisk_aktivitet',
'tema_samlere_entusiaster_og_oppfinnere', 'tema_vitenskap',
'relasjoner', 'type_musikere', 'type_mat', 'type_dyr', 'antall_menn',
'antall_kvinner', 'tema_natur_og_friluftsliv', 'tema_kjop_og_salg',
'type_landbruk_og_fiske', 'offentlige_tjenester_og_veldedighet',
'hovedperson1_kjonn', 'hovedperson2_kjonn', 'hovedperson3_kjonn',
'hovedperson1_alder', 'hovedperson2_alder', 'hovedperson3_alder',
'tema_politikk_og_media'],
dtype='object')
Her ser vi at det som har plass (indeks) i kolonnene blir oppgitt som en liste, som til sist inneholder dtype='object' som forteller at datatypen er et objekt, altså en tekststreng.
Radene (“enhetene”)#
Når vi printer en hel dataframe, vil
Python stort sett automatisk vise oss noen av de første og noen av de siste radene. De første radene
i en dataframe kan også vises ved bruk av .head()-metoden. Tilsvarende vises de siste radene med
.tail()-metoden. Metodene .head() og .tail() har heltall som parametertype. F.eks.
.head(10) viser de første ti radene. Standardverdien her (hvis man ikke oppgir antall) er fem.
1df.head(10)
| aar | video_url | kommune | tittel | tema | hva_er_spesielt | folelse | antrekk | type_bygg_og_industri | type_historisk | ... | tema_kjop_og_salg | type_landbruk_og_fiske | offentlige_tjenester_og_veldedighet | hovedperson1_kjonn | hovedperson2_kjonn | hovedperson3_kjonn | hovedperson1_alder | hovedperson2_alder | hovedperson3_alder | tema_politikk_og_media | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Bergen | Rypejakt | Natur og friluftsliv | NaN | NaN | Caps | NaN | NaN | ... | NaN | NaN | NaN | Mann | Mann | NaN | 10 til 15 | 40 til 50 | NaN | NaN |
| 1 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Sirdal | Kraftutbygging | Bygg og industri | NaN | NaN | Hjelm | Anlegg, Kraftproduksjon | NaN | ... | NaN | NaN | NaN | Mann | NaN | NaN | 40 til 50 | NaN | NaN | NaN |
| 2 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Øksnes | Fraflyttingstilskudd | Politikk | NaN | NaN | Caps, Slips | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | Distriktspolitikk, Samferdselspolitikk |
| 3 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Orkdal | Trønderlån | Kunst og Håndverk | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | Kvinne | Kvinne | NaN | 40 til 50 | 40 til 50 | NaN | NaN |
| 4 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Finnøy | Dyrking av tomater | Landbruk og fiske | NaN | NaN | NaN | NaN | NaN | ... | NaN | Grønnsaker og urter, Tomat | NaN | Mann | Mann | NaN | 30 til 40 | 40 til 50 | NaN | NaN |
| 5 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Østre Toten | Nydyrking | Landbruk og fiske | NaN | NaN | Caps | NaN | NaN | ... | NaN | Åker og jorder og nydyrking | NaN | Mann | NaN | NaN | 40 til 50 | NaN | NaN | NaN |
| 6 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Stranda | Etter turistsesongen | Natur og friluftsliv | Spesiell latter | NaN | Caps, Hjelm | NaN | NaN | ... | NaN | NaN | NaN | Mann | Mann | NaN | 30 til 40 | 80 til 90 | NaN | NaN |
| 7 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Bergen | Bomullsveveri | Bygg og industri | NaN | NaN | Caps, Slips | Tekstilproduksjon | NaN | ... | NaN | NaN | NaN | Mann | NaN | NaN | 40 til 50 | NaN | NaN | NaN |
| 8 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450046... | Øvre Eiker | Elgjakt | Natur og friluftsliv | NaN | NaN | Caps | NaN | NaN | ... | NaN | NaN | NaN | Kvinne | NaN | NaN | 40 til 50 | NaN | NaN | NaN |
| 9 | 1976 | https://tv.nrk.no/serie/norge-rundt/FREP450047... | Bodø | Havørner | Dyr | NaN | NaN | Hatt | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
10 rows × 32 columns
✍️ Oppgave: Finn omfang, kolonner og rader i datasettet i din egen notebook, ved å kopiere inn koden i cellene over. Legg inn et tall i parantesene i .head()
Utdrag av en dataframe#
Utdrag av kolonnene#
Noen ganger er vi kun interessert i enten å se, eller å jobbe videre med, bare noen av kolonnene i en dataframe.[2] Da kan vi opprette en ny dataframe som utgjør dette utdraget. Eksemplet under viser kun verdiene i kommune-kolonnen (de fem første og de fem siste radene vises):
1df['kommune']
0 Bergen
1 Sirdal
2 Øksnes
3 Orkdal
4 Finnøy
...
10214 Sund
10215 Porsgrunn
10216 Lyngdal
10217 Stjørdal
10218 Hå
Name: kommune, Length: 10219, dtype: object
Vi kan avgrense til noen av kolonnene ved å liste opp kolonnenavnene.
Husk at [] brukes for å avgrense lister i Python.
1df[['aar', 'kommune', 'tittel']]
| aar | kommune | tittel | |
|---|---|---|---|
| 0 | 1976 | Bergen | Rypejakt |
| 1 | 1976 | Sirdal | Kraftutbygging |
| 2 | 1976 | Øksnes | Fraflyttingstilskudd |
| 3 | 1976 | Orkdal | Trønderlån |
| 4 | 1976 | Finnøy | Dyrking av tomater |
| ... | ... | ... | ... |
| 10214 | 2016 | Sund | Campingliv (mellomstikk) |
| 10215 | 2016 | Porsgrunn | Louie the Skipper |
| 10216 | 2016 | Lyngdal | Paulsens hotell |
| 10217 | 2016 | Stjørdal | Dugnadsgjengen Stjørdal museum Værnes |
| 10218 | 2016 | Hå | Gitarmuseum |
10219 rows × 3 columns
Resultatet her er en dataframe. Hvis vi vet at vi kun er interessert i å jobbe videre med noen av kolonnene, kan vi opprette en ny dataframe, som vi legger i en ny variabel. Den nye dataframe’n inneholder alle radene fra den opprinnelig dataframe, men kun tre kolonner.
1df_liten = df[['aar', 'kommune', 'tittel']]
2
3df_liten.columns
Index(['aar', 'kommune', 'tittel'], dtype='object')
✍️ Oppgave: Kopier inn innholdet i cellene over i din egen notebook. Men velg “tema” istedet for “tittel” som den siste kolonnen.
Utdrag av radene (filtrering)#
En annen type utdrag fra en dataframe er å vise et utvalg av radene basert på verdier i èn (eller flere) av kolonnene. Dette kalles filtrering. Under er vi kun interessert i innslag fra Bergen, og avgrenser derfor til rader der kolonnen kommune har Bergen som verdi. Under resultatet vises antall rader som oppfyller avgrensningen. Dvs. det finnes 777 innslag som er tatt opp i Bergen.
⚠️ Merk! For å filtrere må vi først si hvilken dataframe vi vil filtrere og deretter i [] definere hvilken kolonne i den dataframen som skal filtreres. Derfor må vi skrive df_liten inne i [] også.
1df_liten[df_liten['kommune'] == 'Bergen']
| aar | kommune | tittel | |
|---|---|---|---|
| 0 | 1976 | Bergen | Rypejakt |
| 7 | 1976 | Bergen | Bomullsveveri |
| 50 | 1977 | Bergen | Bompenger |
| 67 | 1977 | Bergen | Vannmangel |
| 166 | 1977 | Bergen | Pasienter på venteliste |
| ... | ... | ... | ... |
| 10182 | 2016 | Bergen | Fra selvplukk til restaurantmat (mellomstikk) |
| 10194 | 2016 | Bergen | 95-åring går til topps på Ulriken |
| 10197 | 2016 | Bergen | Norges største tunnelboremaskin (mellomstikk) |
| 10205 | 2016 | Bergen | 95-åring går til topps på Ulriken |
| 10208 | 2016 | Bergen | Norges største tunnelboremaskin (mellomstikk) |
777 rows × 3 columns
⚠️ Merk! Radene er fortsatt nummerert med innførselsnummeret de har i det originale datasettet.
Et filter kan legges i en egen variabel. Dette kan øke lesbarheten av koden. Flere
filtre kan også kombineres med boolske operatorer. & brukes for OG mens | brukes
for ELLER.[3] Kombinasjonen under avgrenser til rader der kommunen er
Bergen samtidig som årstallet er før 1980.
Her vil vi filtrere på bare Bergen kommune og bare innslag som er før 1980
1filter1 = df_liten['kommune'] == 'Bergen'
2filter2 = df_liten['aar'] < 1980
3
4df_liten[filter1 & filter2]
| aar | kommune | tittel | |
|---|---|---|---|
| 0 | 1976 | Bergen | Rypejakt |
| 7 | 1976 | Bergen | Bomullsveveri |
| 50 | 1977 | Bergen | Bompenger |
| 67 | 1977 | Bergen | Vannmangel |
| 166 | 1977 | Bergen | Pasienter på venteliste |
| 204 | 1977 | Bergen | Loddefjord |
| 219 | 1978 | Bergen | Byttebutikk i Åsane |
| 257 | 1978 | Bergen | Datakontroll av fiskeflåten hos Fiskeridirekto... |
| 272 | 1978 | Bergen | Buekorpsgutten Jacob Torsvik |
| 283 | 1978 | Bergen | Seilskipet Statsraad Lehmkuhl forfaller |
| 324 | 1978 | Bergen | Fana: Ambulerende servicetiltak for eldre |
| 373 | 1978 | Bergen | Åsane: Mesterskap i ludo |
| 435 | 1979 | Bergen | Bergen/Alvøen: Produksjon av pengesedler |
| 436 | 1979 | Bergen | Bergen/Breistein: Amatørteater på Vestlandsheimen |
| 445 | 1979 | Bergen | Agnete Tjærandsen besøker Bergen(mellomstikk) |
| 457 | 1979 | Bergen | Bussemennene - sporveistiltak for eldre |
| 471 | 1979 | Bergen | Strilene inntar byen |
| 475 | 1979 | Bergen | Ferieklubb for barn |
| 521 | 1979 | Bergen | Blomsterdekorering |
Hvis vi bare skal se på innslag fra Bergen fra en gitt tidsperiode trenger vi ikke ha en kolonne som forteller at innslaget er fra Bergen. Da kan vi fjerne den kolonnen. Rader og kolonner kan avgrenses i samme kommando. Under bruker vi det samme filteret som i forrige skjermbilde,
men begrenser visningen til to kolonner. Her legger vi listen av kolonner i en egen variabel, cols.
Vi avslutter kommandoen med .head() for å kun vise de første fem radene.
1filter1 = df_liten['kommune'] == 'Bergen'
2filter2 = df_liten['aar'] < 1980
3
4cols = ['tittel', 'aar']
5
6df_liten[filter1 & filter2][cols].head()
| tittel | aar | |
|---|---|---|
| 0 | Rypejakt | 1976 |
| 7 | Bomullsveveri | 1976 |
| 50 | Bompenger | 1977 |
| 67 | Vannmangel | 1977 |
| 166 | Pasienter på venteliste | 1977 |
✍️ Oppgave: Gjør det samme i din egen notebook, men velg en annen kommune enn Bergen. Husk at hvis du kopierer må du også endre “tittel” til “tema”.
Eksportere til en ny CSV-fil#
Kanskje er det slik at du ønsker å vaske et mindre datasett i OpenRefine, eller rett og slett lagre dataframen som et nytt datasett? Du bruker da funksjonen df.to_csv('ønsketnavnpåfilen.csv'). Du kan også spesifisere adresse før navnet, om det er et spesielt sted du ønsker å lagre filen. df erstattes med navnet på dataframen du ønsker å eksportere til å bli en fil (Ja, det kan også bare være df (hoved-dataframe) om du kun har gjort endringer i den).
✍️ Oppgave: Lag en CSV-fil av df_liten. Opprett en ny notebook og les inn filen som df (hoved-dataframe) for den nye notebooken.
Flere datatyper i Pandas#
Series#
En enkel kolonne utgjør en Pandas-Series. Når vi foretar redigeringer i en kolonne bruker vi gjerne enten Pandas-funksjoner som er definert
med en Serie “i tankene” eller metoder som er definert for datatypen “Series”. Vi starter med å se på årstall-kolonnen i df, df['aar']
1df['aar'].head()
0 1976
1 1976
2 1976
3 1976
4 1976
Name: aar, dtype: int64
Vi ser at ‘aar’ er en tallkolonne.
Hvis vi ønsker å konvertere alle datoangivelser i en kolonne til datatypen datetime, kan vi bruke pandas-funksjonen to_datetime().
1#Kjør en pandas-funksjon som konverterer en tallkolonne til en datokolonne
2df['aar'] = pd.to_datetime(df['aar'])
3
4df['aar'].head()
0 1970-01-01 00:00:00.000001976
1 1970-01-01 00:00:00.000001976
2 1970-01-01 00:00:00.000001976
3 1970-01-01 00:00:00.000001976
4 1970-01-01 00:00:00.000001976
Name: aar, dtype: datetime64[ns]
Kolonnen representerer nå årstallene som tidsinnførsler (1. januar er valgt per default som dato).
Vi kan også eksportere serien til en liste for bruk utenfor pandas. Dette gjør vi med metoden to_list() definert i Series-klassen
1#Kjør en pandas _metode_ som gjør series om til en liste.
2datoliste = df['aar'].to_list()
3datoliste[:5]
[Timestamp('1970-01-01 00:00:00.000001976'),
Timestamp('1970-01-01 00:00:00.000001976'),
Timestamp('1970-01-01 00:00:00.000001976'),
Timestamp('1970-01-01 00:00:00.000001976'),
Timestamp('1970-01-01 00:00:00.000001976')]
Index#
En Index gjør det mulig å referere til enkeltrader, enkeltkolonner, enkeltceller og grupper av
slike i en dataframe. Enhver dataframe, selv de enkleste av de, har en Index. Det finnes
forskjellige innebygde indekstyper i Pandas for å svare til forskjellige behov. Som regel opprettes indeksen
automatisk basert på strukturen i dataene. I tidligere eksempel,
ser vi en indeks som er basert på kolonnenavnene
i CSV-filens første rad. Under oppretter vi en dataframe basert på en liste av tupler fra et tidligere eksempel.
Denne får automatisk en RangeIndex, som er en enkel ordenstallbasert indeks.
1sportsvarer = [] # Liste med tupler
2
3sportsvarer.append(('Fotballer', 95.0, 5))
4sportsvarer.append(('Shorts', 89.0, 12))
5sportsvarer.append(('Trøyer', 74.0, 15))
6
7print(sportsvarer)
[('Fotballer', 95.0, 5), ('Shorts', 89.0, 12), ('Trøyer', 74.0, 15)]
1df_sport = pd.DataFrame(sportsvarer)
2
3print(df_sport),
4print('kolonneindeksen:', df_sport.columns)
0 1 2
0 Fotballer 95.0 5
1 Shorts 89.0 12
2 Trøyer 74.0 15
kolonneindeksen: RangeIndex(start=0, stop=3, step=1)
Mer kompliserte dataframes, hvor kolonnene har en gruppering vil få en MultiIndex,
som er en indeks med flere nivåer, hvor det øverste nivået ville være kolonnegruppen og
det nederste nivået enkeltkolonnen. Eksempel på en MultiIndex vises i avsnittet om gruppering lenger ned i kapittelet.
Fordi aar er et heltall kan vi bruke > og < i filter, se tidligere eksempel i
skjermbildet
Analyse av kolonner med tall#
For å få oversikt over en kolonne som har en tallmessig datatype kan
vi bruke .describe()-metoden.
1df[['antall_menn', 'antall_kvinner']].describe()
| antall_menn | antall_kvinner | |
|---|---|---|
| count | 9013.000000 | 6898.000000 |
| mean | 7.600466 | 7.959409 |
| std | 11.243148 | 11.993381 |
| min | 1.000000 | 1.000000 |
| 25% | 2.000000 | 2.000000 |
| 50% | 4.000000 | 4.000000 |
| 75% | 10.000000 | 10.000000 |
| max | 100.000000 | 100.000000 |
Ønsker du å bare vise en form for tallmessig beskrivelse kan du velge funksjonene hver for seg.
Bruk .median()-metoden for å finne median for verdiene i en kolonne.
1df['antall_kvinner'].median()
4.0
Under er en oversikt over tallmessige beskrivelser man kan benytte seg av:
Metode |
Beskrivelse |
|---|---|
.median() |
|
.mean() |
gjennomsnittsverdien |
.count() |
antall rader for hvilke kolonnen har en verdi (ikke tom) |
.sum() |
- |
.min() |
- |
.max() |
- |
.quantile(0.25) |
- |
.quantile(0.75) |
- |
Under bruker vi .sum() i en Python-celle for å regne ut prosentvis fordeling
mellom menn og kvinner. Her tolker vi tomme celler som 0.
1total_antall_kvinner = df['antall_kvinner'].sum()
2total_antall_menn = df['antall_menn'].sum()
3
4total_antall = total_antall_kvinner + total_antall_menn
5
6kvinner_prosent = (total_antall_kvinner / total_antall) * 100
7menn_prosent = (total_antall_menn / total_antall) * 100
8
9print('Kvinner prosent:', kvinner_prosent)
10print('Menn prosent:', menn_prosent)
Kvinner prosent: 44.49018289075985
Menn prosent: 55.50981710924015
Analyse av kolonner med tekst#
Hvis vi bruker .describe()-metoden på en kolonne som inneholder tekst,
får vi en annen type statistikk:
1df['kommune'].describe()
count 10219
unique 431
top Bergen
freq 777
Name: kommune, dtype: object
Her angir count antallet verdier i kolonnen. Dette kan være relevant for å se manglende
data. Oversikten viser også antall unike verdier og verdien med høyest frekvens.
I dette eksempel er det Bergen som har høyest frekvens med 777 forekomster.
Metoden unique() gir oss alle unike verdier i kolonnen.
1df['kommune'].unique()
array(['Bergen', 'Sirdal', 'Øksnes', 'Orkdal', 'Finnøy', 'Østre Toten',
'Stranda', 'Øvre Eiker', 'Bodø', 'Ullensvang', 'Vardø', 'Tønsberg',
'Fet', 'Kviteseid', 'Karmøy', 'Lillesand', 'Ukjent sted', 'Tromsø',
'Bærum', 'Trondheim', 'Dovre', 'Loppa', 'Lenvik', 'Askim',
'Kristiansund', 'Vadsø', 'Sund', 'Alstahaug', 'Flora', 'Jan Mayen',
'Karasjok', 'Valle', 'Ringsaker', 'Sandnes', 'Stordal', 'Sandøy',
'Arendal', 'Herøy (Nordl.)', 'Hole', 'Sula', 'Hå', 'Kristiansand',
'Hjelmeland', 'Hvaler', 'Namsos', 'Sogndal', 'Halden',
'Oslokommune', 'Fræna', 'Sortland', 'Båtsfjord', 'Lillehammer',
'Verran', 'Rygge', 'Alta', 'Ringerike', 'Elverum', 'Fauske',
'Øystre Slidre', 'Ullensaker', 'Stryn', 'Ulvik', 'Sola', 'Åmot',
'Ibestad', 'Leikanger', 'Porsgrunn', 'Lierne', 'Snillfjord',
'Vågan', 'Tranøy', 'Ringebu', 'Ås', 'Tana', 'Røst', 'Hitra',
'Tinn', 'Eid', 'Levanger', 'Nøtterøy', 'Marnardal', 'Balsfjord',
'Inderøy', 'Vestnes', 'Bindal', 'Tysvær', 'Larvik',
'Herøy (M.ogR.)', 'Hamar', 'Lund', 'Kåfjord', 'Tysnes', 'Engerdal',
'Kongsberg', 'Nordreisa', 'Utlandet', 'Etne', 'Horten', 'Rennebu',
'Seljord', 'Hasvik', 'Frosta', 'Rakkestad', 'Stavanger',
'Kongsvinger', 'Skien', 'Rissa', 'Holmestrand', 'Saltdal', 'Eide',
'Porsanger', 'Kvitsøy', 'Årdal', 'Farsund', 'Molde', 'Ål',
'Søndre Land', 'Rana', 'Gausdal', 'Drammen', 'Sør-Varanger',
'Hyllestad', 'Klepp', 'Rauma', 'Bjugn', 'Sør-Aurdal',
'Bø (Telem.)', 'Rendalen', 'Vindafjord', 'Svalbard', 'Torsken',
'Vefsn', 'Mandal', 'Fredrikstad', 'Stange', 'Lindås', 'Hol',
'Trysil', 'Nannestad', 'Frøya', 'Songdalen', 'Selje', 'Luster',
'Kvæfjord', 'Gjerstad', 'Notodden', 'Samnanger', 'Nesna', 'Røros',
'Skjervøy', 'Gol', 'Kragerø', 'Gamvik', 'Surnadal', 'Bømlo',
'Snåsa', 'Nordsjøen', 'Eidsberg', 'Hammerfest', 'Meråker', 'Selbu',
'Harstad', 'Kautokeino', 'Karlsøy', 'Våler (Hedm.)', 'Tvedestrand',
'Vinje', 'Kvam', 'Melhus', 'Grimstad', 'Ålesund', 'Vestre Slidre',
'Nordkapp', 'Forsand', 'Lyngdal', 'Time', 'Hadsel', 'Flakstad',
'Bamble', 'Lyngen', 'Haugesund', 'Eidfjord', 'Asker', 'Froland',
'Ørland', 'Trøgstad', 'Overhalla', 'Sarpsborg', 'Modum',
'Spydeberg', 'Gjemnes', 'Nordre Land', 'Tingvoll', 'Sørreisa',
'Lørenskog', 'Voss', 'Tjøme', 'Volda', 'Andøy', 'Sauda', 'Skjåk',
'Midtre Gauldal', 'Bardu', 'Suldal', 'Sandefjord', 'Oppegård',
'Eigersund', 'Giske', 'Vanylven', 'Eidskog', 'Narvik',
'Kvinnherad', 'Berg', 'Lunner', 'Hemnes', 'Smøla', 'Åmli', 'Åsnes',
'Gjøvik', 'Bygland', 'Måsøy', 'Oppdal', 'Moss', 'Lebesby',
'Hamarøy', 'Flatanger', 'Hurum', 'Vang', 'Kvinesdal', 'Tynset',
'Aure', 'Lurøy', 'Fitjar', 'Nes(Busk.)', 'Hattfjelldal',
'Tjeldsund', 'Flekkefjord', 'Gran', 'Andebu', 'Nord-Odal', 'Øyer',
'Aurskog-Høland', 'Evje og Hornnes', 'Bykle', 'Tokke', 'Jondal',
'Jølster', 'Radøy', 'Frogn', 'Vågsøy', 'Førde', 'Målselv', 'Haram',
'Granvin', 'Hemsedal', 'Aurland', 'Nesset', 'Vik', 'Lesja',
'Sigdal', 'Beiarn', 'Øygarden', 'Løten', 'Hjartdal', 'Naustdal',
'Røyken', 'Jevnaker', 'Vestvågøy', 'Gloppen', 'Steinkjer',
'Norddal', 'Askvoll', 'Leksvik', 'Skodje', 'Bjerkreim',
'Lindesnes', 'Randaberg', 'Vågå', 'Råde', 'Sør-Fron', 'Værøy',
'Sel', 'Sunndal', 'Grue', 'Vestre Toten', 'Rennesøy', 'Stjørdal',
'Averøy', 'Nome', 'Aremark', 'Nittedal', 'Fyresdal', 'Krødsherad',
'Stokke', 'Odda', 'Salangen', 'Berlevåg', 'Osterøy', 'Vaksdal',
'Skedsmo', 'Gratangen', 'Stord', 'Eidsvoll', 'Nes(Ak.)', 'Alvdal',
'Sveio', 'Gjesdal', 'Askøy', 'Sørum', 'Dønna', 'Vegårshei',
'Søgne', 'Evenes', 'Hobøl', 'Dyrøy', 'Lom', 'Vestby', 'Balestrand',
'Nore og Uvdal', 'Sauherad', 'Steigen', 'Os (Hord.)', 'Ørsta',
'Ørskog', 'Våler (Østf.)', 'Hof', 'Tydal', 'Rollag', 'Sørfold',
'Nord-Aurdal', 'Stor-Elvdal', 'Hornindal', 'Strand', 'Vennesla',
'Etnedal', 'Drangedal', 'Rødøy', 'Ski', 'Hurdal', 'Rælingen',
'Lier', 'Fjaler', 'Bø (Nordl.)', 'Marker', 'Holtålen', 'Høyanger',
'Skiptvet', 'Meldal', 'Sykkylven', 'Brønnøy', 'Siljan', 'Tysfjord',
'Nedre Eiker', 'Sande (Vestf.)', 'Nissedal', 'Vikna', 'Audnedal',
'Skaun', 'Kvænangen', 'Ulstein', 'Meløy', 'Halsa', 'Risør',
'Gaular', 'Tolga', 'Enebakk', 'Røyrvik', 'Høylandet', 'Fjell',
'Lødingen', 'Nesseby', 'Fusa', 'Sør-Odal', 'Aukra', 'Birkenes',
'Os (Hedm.)', 'Storfjord', 'Svelvik', 'Folldal', 'Masfjorden',
'Bremanger', 'Rindal', 'Lærdal', 'Namsskogan', 'Åseral', 'Re',
'Bjørnøya', 'Sokndal', 'Nord-Fron', 'Skånland', 'Utsira', 'Gulen',
'Verdal', 'Nærøy', 'Moskenes', 'Fedje', 'Nesodden', 'Grong',
'Sande (M.ogR.)', 'Lavangen', 'Vega', 'Lardal', 'Klæbu', 'Meland',
'Modalen', 'Austevoll', 'Malvik', 'Træna', 'Fosnes', 'Hareid',
'Austrheim', 'Midsund', 'Flesberg', 'Flå', 'Osen', 'Solund',
'Hægebostad', 'Ballangen', 'Iveland', 'Gildeskål', 'Rømskog',
'Hemne', 'Oslo Fredrikstad', 'Vevelstad', 'Namdalseid', 'Åfjord',
'Leirfjord', 'Sømna', 'Grane', 'Kjøllefjord', 'Leka'], dtype=object)
For å få en liste over unike verdier sortert etter frekvens, kan vi bruke
.value_counts()-metoden. Visningen nedenfor sorteres på
frekvens, og viser verdiene med de fem høyeste og fem laveste frekvenser.
1df['kommune'].value_counts()
Bergen 777
Oslokommune 735
Ukjent sted 585
Trondheim 248
Stavanger 223
...
Røyrvik 1
Sømna 1
Grane 1
Kjøllefjord 1
Leka 1
Name: kommune, Length: 431, dtype: int64
Vi kan legge til .head() eller .tail() for å se utdrag av verdiene. F.eks. for
å se de 20 kommunene med høyest frekvens.
1df['kommune'].value_counts().head(20)
Bergen 777
Oslokommune 735
Ukjent sted 585
Trondheim 248
Stavanger 223
Kristiansand 180
Tromsø 159
Fredrikstad 156
Bodø 122
Lillehammer 104
Skien 98
Porsgrunn 88
Utlandet 86
Ålesund 85
Arendal 81
Bærum 79
Drammen 76
Svalbard 70
Sør-Varanger 67
Sarpsborg 63
Name: kommune, dtype: int64
✍️ Oppgave: Gjør det samme som over med kolonnen “tema”.
Alternativt kan vi vise relativ frekvens
I eksemplet i brukes normalize-parameteren med boolsk verdi True.
1df['kommune'].value_counts(normalize = True).head(10)
Bergen 0.076035
Oslokommune 0.071925
Ukjent sted 0.057246
Trondheim 0.024269
Stavanger 0.021822
Kristiansand 0.017614
Tromsø 0.015559
Fredrikstad 0.015266
Bodø 0.011939
Lillehammer 0.010177
Name: kommune, dtype: float64
Frekvensene kan lagres som en dataframe ved hjelp av
.to_frame()-metoden.
1df_temp = df['kommune'].value_counts(normalize = True).head(15).to_frame()
2df_temp
| kommune | |
|---|---|
| Bergen | 0.076035 |
| Oslokommune | 0.071925 |
| Ukjent sted | 0.057246 |
| Trondheim | 0.024269 |
| Stavanger | 0.021822 |
| Kristiansand | 0.017614 |
| Tromsø | 0.015559 |
| Fredrikstad | 0.015266 |
| Bodø | 0.011939 |
| Lillehammer | 0.010177 |
| Skien | 0.009590 |
| Porsgrunn | 0.008611 |
| Utlandet | 0.008416 |
| Ålesund | 0.008318 |
| Arendal | 0.007926 |
✍️ Oppgave: Gjør det samme som over, bare for kolonnen “tema”.
Denne dataframen er indeksert med kommunenavnet som nøkkel. Slike dataframes brukes for eksempel i visualiseringer: Nedenfor oppretter vi en ny konnene i den nylagde dataframen, Procent som tar prosenttall. Til slutt lages et enkelt stoplediagram.
1df_temp['procent'] = df_temp['kommune'] * 100
2df_temp['procent'].plot(kind = 'bar')
<Axes: >
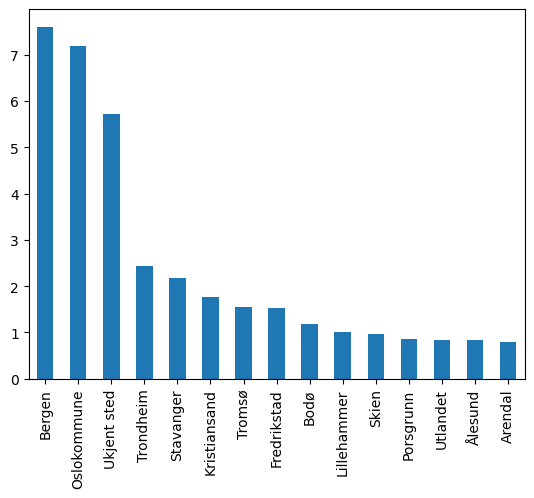
Du kan lese mer om visualisering i neste kapittel. Her gir vi kun en smakebit.
Gruppering#
I denne gjenngangen bruker vi data fra ODA, OsloMets institusjonelle arkiv. Vi har hentet ut data som vi så laget lagret i en CSV-fil.
Du finner csv-filen på toppen av dette kapitlet.
Dataframen består av 3149 rader (oppgaver) og 15 kolonner:
1df_oda = pd.read_csv('data/oda-master-thesis.csv', sep = ',')
2
3df_oda.columns
Index(['Title', 'Identifier', 'Creators', 'Supervisors', 'Lang', 'Subjects',
'SubjectsVDP', 'Date', 'Institute', 'FacultyShort', 'FacultyLong',
'InstituteShort', 'InstituteLong', 'MasterProg', 'LangNorm'],
dtype='object')
Kolonnen Lang lagrer språket oppgaven er skrevet på:
1df_oda['Lang'].value_counts()
nb 2396
en 695
nn 47
da 4
se 3
Name: Lang, dtype: int64
Kolonnen LangNorm har en forenklet versjon av språk der koden ‘nb’ og ‘nn’ er mappet til ‘nor’; ‘en’ er mappet til ‘eng’; og andre verdier er mappet til ‘oth’. Relativ frekvens for denne kolonnen viser at 77 prosent av oppgavene er skrevet på norsk, 22 prosent på engelsk, og mindre en 1 prosent på andre språk.
1df_oda['LangNorm'].value_counts(normalize = True)
nor 0.775802
eng 0.220705
oth 0.003493
Name: LangNorm, dtype: float64
Er fordelingen på språk likt mellom fakulteter? Vi kan bruke .groupby()-metoden for å vise
språkfordelingen for hvert fakultet. Vi ser
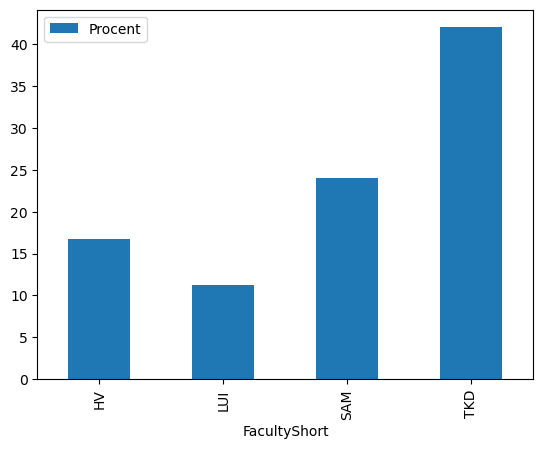
at LUI (Fakultet for lærerutdanning og internasjonale studier) har den størst andel av
oppgaver på norsk, 88%, mens TKD (Fakultet for teknologi, kunst og design) har 57,5% på norsk.
1df_oda.groupby('FacultyShort')['LangNorm'].value_counts(normalize = True)
FacultyShort LangNorm
HV nor 0.829448
eng 0.166871
oth 0.003681
LUI nor 0.887324
eng 0.112676
SAM nor 0.754650
eng 0.240035
oth 0.005314
TKD nor 0.575758
eng 0.420202
oth 0.004040
Name: LangNorm, dtype: float64
I det følgende lagrer vi analyseresultater i en nyopprettet dataframe.
Her brukes .to_frame() for å legge resultatet i en ny dataframe. Vanligvis
er indeksen - identifikatoren for raden - et heltall. Dette er nummeret 0, 1, 2,
osv. som vises til venstre for radene. Når vi bruker .groupby() gjøres verdiene
i kolonnen som er parameter til .groupby() om til en indeks. Fordi vi grupperer
fakultet kombinert med språk, lages det en MultiIndex av FacultyShort og
LangNorm.
Kolonnen med relativfrekvens kalles også LangNorm. Vi bruker .rename()-metoden for å
endre navnet på denne kolonnen fra LangNorm til RelativeFreq
Parameteren til .rename() er en dict med det gamle kolonnenavnet som nøkkel
og det nye kolonnenavnet som verdi. Altså, etter å først gruppere, så oppretter vi en dict vi kaller for col_map. Denne dict’en inneholder nye navn på kolonner.
Deretter
.inplace-parameter bestemmer om vi
skal oppdatere dataframe (True), eller kun se resultatet (False, standardverdi).
Til slutt legger vi inn en ny kolonne hvor andelene er omregnet til prosenter. Da får vi en ny dataframe med nye navn på to kolonner, og en helt ny kolonne med ny data lagt til.
1df2_oda = df_oda.groupby('FacultyShort')['LangNorm'].value_counts(normalize = True).to_frame()
2col_map = {
3 'LangNorm' : 'RelativeFreq'
4}
5df2_oda.rename(columns = col_map, inplace = True)
6df2_oda['Procent'] = df2_oda['RelativeFreq'] * 100
7print(df2_oda)
8df2_oda.index
RelativeFreq Procent
FacultyShort LangNorm
HV nor 0.829448 82.944785
eng 0.166871 16.687117
oth 0.003681 0.368098
LUI nor 0.887324 88.732394
eng 0.112676 11.267606
SAM nor 0.754650 75.465013
eng 0.240035 24.003543
oth 0.005314 0.531444
TKD nor 0.575758 57.575758
eng 0.420202 42.020202
oth 0.004040 0.404040
MultiIndex([( 'HV', 'nor'),
( 'HV', 'eng'),
( 'HV', 'oth'),
('LUI', 'nor'),
('LUI', 'eng'),
('SAM', 'nor'),
('SAM', 'eng'),
('SAM', 'oth'),
('TKD', 'nor'),
('TKD', 'eng'),
('TKD', 'oth')],
names=['FacultyShort', 'LangNorm'])
I visse situasjoner passer det ikke å jobbe med en MultiIndex. Da kan vi bruke .reset_index()
( se cellen nedenfor ),
og gjør MultiIndex-kolonnene til vanlige datakolonner (Se tallene til venstre).
1df2_oda = df2_oda.reset_index()
I neste kapittel skal vi se hvordan disse data kan visualiseres med utvidelsen Plotly. Her er en enkel visualisering støttet direkte av Pandas. I cellen nedenfor ser vi hvordan andelen av de engelskspråkelige oppgaver er på tvers av fakultetene ved å avgrense til engelsk språk.
1filter1 = df2_oda['LangNorm'] == 'eng'
2
3df2_oda[filter1].plot(kind = 'bar', x = 'FacultyShort', y = 'Procent')
<Axes: xlabel='FacultyShort'>
Ved å bruke .sort_values()-metoden ( se cellen nedenfor )
kan vi sortere resultatet. Parametere til .sort_values() er kolonnen eller kolonnene
det skal sorteres etter, og om det skal sorteres i stigende (ascending = True,
standardverdi) eller fallende rekkefølge (ascending = False).
1filter1 = df2_oda['LangNorm'] == 'eng'
2
3df2_oda[filter1].sort_values('Procent', ascending = False)
| FacultyShort | LangNorm | RelativeFreq | Procent | |
|---|---|---|---|---|
| 9 | TKD | eng | 0.420202 | 42.020202 |
| 6 | SAM | eng | 0.240035 | 24.003543 |
| 1 | HV | eng | 0.166871 | 16.687117 |
| 4 | LUI | eng | 0.112676 | 11.267606 |
Behandling av kolonner som inneholder flere verdier#
En masteroppgave kan ha flere emner. Dette løses i en CSV-fil ved å samle alle emnene i samme kolonne og bruke et internt
skilletegn for å skille dem. I dette tilfelle
brukes | som skilletegn i kolonnen.
Det kan være at vi trenger å lage kolonner for hvert emne, slik at vi senere lettere kan lage utdrag. Merk at dette også er mulig å gjøre gjennom OpenRefine, og ble gjennomgått i forrige kapittel. Men i de tilfeller der man oppdager at man trenger å gjøre det mens man jobber med et datasett i Jupiter Notebooks, kan det være raskere å gjennomføre slik behandling direkte ved bruke av Pandas. Men man står fritt til å også gå veien om OpenRefine, om man ønsker.
1cols = ['Title', 'Subjects']
2
3df_oda[cols].head(5)
| Title | Subjects | |
|---|---|---|
| 0 | «Risikofaktorer og komplikasjoner knyttet til ... | Peripherally inserted central catheter|Infeksj... |
| 1 | Når barnet ikke vil. En kvalitativ masteroppga... | Barneanestesi|tvang|Anestesisykepleie |
| 2 | Oksykodon versus fentanyl – hvilket opioid adm... | Laparoskopisk kirurgi|Fentanyl|Oksykodon|Posto... |
| 3 | Kartlegging og evaluering av standardisert sme... | Ryggfiksasjon|Ryggkirurgi|Anestesi|Postoperati... |
| 4 | Anestesisykepleierens funksjon ved innleggelse... | Perifert venekateter|Ressurdsforvaltning|Tidsf... |
I cellen nedenfor brukes .str.split()-metoden for å dele
opp kolonnen basert på et gitt skilletegn. Hver verdi legges så i sin egen kolonne.
Det første emnet legges i kolonnen 0, den neste i 1, osv. Nederst ser vi at antallet
kolonner er 24, dvs masteroppgaven med flest emner hadde 24 emner. Vi ser at masteroppgaven
med indeks 1, andre rad, har kun tre emner. Alle andre kolonner (for eksempel
3-24 for oppgaven med index 1) får tilordnet spesialverdien None.
1df_oda_splitted = df_oda['Subjects'].str.split('|', expand = True)
2
3df_oda_splitted.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Peripherally inserted central catheter | Infeksjon | Tromboflebitt | Trombose | Okklusjon | None | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 1 | Barneanestesi | tvang | Anestesisykepleie | None | None | None | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 2 | Laparoskopisk kirurgi | Fentanyl | Oksykodon | Postoperative smerter | Postoperativ kvalme | Laparoscopic surgery | Oxycodone | Postoperative pains | Postoperative nausea | None | ... | None | None | None | None | None | None | None | None | None | None |
| 3 | Ryggfiksasjon | Ryggkirurgi | Anestesi | Postoperativ smerte | Multimodal smertelindring | Standardisert smertelindring | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 4 | Perifert venekateter | Ressurdsforvaltning | Tidsforvaltning | Kostnader | None | None | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
5 rows × 24 columns
Hvis vi ønsker å legge dette til i den opprinnelige dataframen kan vi gjøre følgende:
I neste celle , ser vi et eksempel på hvordan
Pandas-funksjonen .concat() kan brukes for å sammenføye den nye df_splitted
dataframen med den opprinnelige df dataframe. Parameteren til .concat() er
en liste av dataframes som skal settes sammen. Den andre parameteren, axis,
bestemmer om de skal kombineres som rader (axis = 0, altså, nedover) eller som
kolonner (axis = 1, altså bortover). Her vil vi legge inn flere kolonner,
altså bortover. Den nye dataframen, df_merged, har både de opprinnelig kolonnene,
f.eks. Title og kolonner fra de oppdelte emner, f.eks. 0.
1df_oda_merged = pd.concat([df_oda, df_oda_splitted], axis = 1)
2
3cols = ['Title', 0]
4
5df_oda_merged[cols].head()
| Title | 0 | |
|---|---|---|
| 0 | «Risikofaktorer og komplikasjoner knyttet til ... | Peripherally inserted central catheter |
| 1 | Når barnet ikke vil. En kvalitativ masteroppga... | Barneanestesi |
| 2 | Oksykodon versus fentanyl – hvilket opioid adm... | Laparoskopisk kirurgi |
| 3 | Kartlegging og evaluering av standardisert sme... | Ryggfiksasjon |
| 4 | Anestesisykepleierens funksjon ved innleggelse... | Perifert venekateter |
Neste trinn er bruk av .melt()-metoden. .melt() gjør om alle emne-kolonnene til
en enkelt kolonne, ved å gjenta øvrige data i radene nedover. Metoden tar to
lister med kolonner som parametre. id_vars er kolonnene som skal gjentas for
hver rad, mens value_vars er kolonnene som skal sammensmeltes til èn. I
vårt eksempel er listen value_vars en sekvens med tall fra 0 til 23. Python-funksjonen range() kan brukes for å generere tallrekken. I vårt tilfelle
ville .melt() gjøre det enkelt å finne alle dokumenter som har
(for eksempel) emneordet Kosthold
1id_vars = ['Title', 'FacultyShort', 'InstituteShort']
2value_vars = list(range(24))
3
4df_oda_melted = df_oda_merged.melt(id_vars = id_vars,
5 value_vars = value_vars)
6
7df_oda_melted.sort_values(['Title', 'variable']).head()
| Title | FacultyShort | InstituteShort | variable | value | |
|---|---|---|---|---|---|
| 583 | "... Grete Roede kurs, liksom. Hallo? Kjerring... | HV | SHA | 0 | Slanking |
| 3732 | "... Grete Roede kurs, liksom. Hallo? Kjerring... | HV | SHA | 1 | Menn |
| 6881 | "... Grete Roede kurs, liksom. Hallo? Kjerring... | HV | SHA | 2 | Kosthold |
| 10030 | "... Grete Roede kurs, liksom. Hallo? Kjerring... | HV | SHA | 3 | Livsstil |
| 13179 | "... Grete Roede kurs, liksom. Hallo? Kjerring... | HV | SHA | 4 | None |
1value_vars = list(range(10))
2
3value_vars
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Resultatet av .melt()-metoden plasserer emneordene i en kolonne som får
navnet value. Kolonnen variable er det opprinnelige kolonnenavnet, dvs. 0,
1, osv. I eksemplet under ser mann en enkelt tittel som har tre emner, de øvrige
21 radene (3, 4, … 23) er lagt inn med None. Bruken av .melt() legger dermed
mange rader uten ny informasjon (se de siste to radene ).
1filter1 = df_oda_melted['Title'].str.contains('Når barnet ikke vil')
2
3df_oda_melted[filter1]
| Title | FacultyShort | InstituteShort | variable | value | |
|---|---|---|---|---|---|
| 1 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 0 | Barneanestesi |
| 3150 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 1 | tvang |
| 6299 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 2 | Anestesisykepleie |
| 9448 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 3 | None |
| 12597 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 4 | None |
| 15746 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 5 | None |
| 18895 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 6 | None |
| 22044 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 7 | None |
| 25193 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 8 | None |
| 28342 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 9 | None |
| 31491 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 10 | None |
| 34640 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 11 | None |
| 37789 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 12 | None |
| 40938 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 13 | None |
| 44087 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 14 | None |
| 47236 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 15 | None |
| 50385 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 16 | None |
| 53534 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 17 | None |
| 56683 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 18 | None |
| 59832 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 19 | None |
| 62981 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 20 | None |
| 66130 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 21 | None |
| 69279 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 22 | None |
| 72428 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | 23 | None |
Antallet rader blir antall rader
i utgangspunktet (df, 3149) ganget med antallet kolonner med gjentatte emner,
som var 24 (0 til 23). Resultatet er 75 576. Vi kan sjekke dette med å bruke
.shape-attribut på de dataframes som er brukt.
1print('Dataframe df:', df_oda.shape)
2print('Dataframe splitted:', df_oda_splitted.shape)
3print('Dataframe merged:', df_oda_merged.shape)
4print('Dataframe melted:', df_oda_melted.shape)
Dataframe df: (3149, 15)
Dataframe splitted: (3149, 24)
Dataframe merged: (3149, 39)
Dataframe melted: (75576, 5)
.isna()-metoden kan brukes for å avgrense dataframe til rader der verdier
mangler. Det motsatte er (og stort sett mer nyttig) er .notna() som avgrenser
til rader som har et verdi. Under anvendes
.notna() på “value”-kolonnen for å fjerne de overflødige radene med tomme emner,
noe som reduserer antallet rader i dataframen fra 75.576 til 16.769.
1df_oda_melted = df_oda_melted[df_oda_melted['value'].notna()]
Her sjekkes kolonnen value for tomme verdier. Dette reduserer dataframe fra 75.576 til 16.769 rader.
For å rydde opp i dataframe fjerner vi variable-kolonnen og omdøper
value-kolonnen til Subject. .drop()-metoden brukes til å fjerne kolonner.
En liste over kolonnene legges til som parameter. Igjen brukes parameteren inplace
for å utføre oppdateringen på dataframe som dermed forandres
1df_oda_melted.drop(columns = ['variable'], inplace = True)
2
3col_map = {
4 'value' : 'Subject'
5}
6
7df_oda_melted.rename(columns = col_map, inplace = True)
8
9df_oda_melted.head()
| Title | FacultyShort | InstituteShort | Subject | |
|---|---|---|---|---|
| 0 | «Risikofaktorer og komplikasjoner knyttet til ... | HV | SHA | Peripherally inserted central catheter |
| 1 | Når barnet ikke vil. En kvalitativ masteroppga... | HV | SHA | Barneanestesi |
| 2 | Oksykodon versus fentanyl – hvilket opioid adm... | HV | SHA | Laparoskopisk kirurgi |
| 3 | Kartlegging og evaluering av standardisert sme... | HV | SHA | Ryggfiksasjon |
| 4 | Anestesisykepleierens funksjon ved innleggelse... | HV | SHA | Perifert venekateter |
Emnene er nå klare for analyse. I cellen nedenfor finner vi er de mest populære emnene for masteroppgaver skrevet ved institutt ABI.
1filter1 = df_oda_melted['InstituteShort'] == 'ABI'
2
3df_oda_melted[filter1]['Subject'].value_counts().head(10)
Bibliotek 16
Folkebibliotek 14
Møteplasser 7
Bibliotekarer 5
Bibliotektjenester 5
Litteratur 5
Informasjonsbehov 4
Informasjonsadferd 4
Norge 4
Holdninger 4
Name: Subject, dtype: int64
I neste kapittel skal vi jobbe videre med CSV-filene ved å gjøre om mønstre til visualiseringer i form av grafer.