9. Visualisering med Plotly#
|
Kapitlet bruker følgende datafiler: oda-master-thesis.csv folkebibl-2020-kommuner.csv |
I dette kapitlet går vi igjennom hvordan visualisere aggregerte mønstre i form av grafer, og gir en inngang til enkle statistiske oversikter.
Det finnes flere Python-moduler som kan brukes for å generere diagramer (stolpediagram, kakediagram, osv.). Noen av de meste kjente er Matplotlib[1], Seaborn[2] og Bokeh[3]. Her skal vi bruke Plotly. Det er også mulig å lage og eksportere csv-filer som kan brukes i eksterne visualiseringsprogrammer. Dette er alt fra verktøy som gir tilgang til hundrevis av tilpassbare måter å visualisere data som hos RawGraphs, til verkøy som er laget for spesifikke typer nettverksanalyser og -visualiseringer, som GephiLite.
En fordel med Plotly er at det lar deg lage interaktive diagramer direkte i Jupyter Notebooks.
Innlasting av modulene og tilrettelegging#
Data som brukes med Plotly kommer fra en Pandas dataframe. Vi må derfor importere både Plotly og Pandas.
1import pandas as pd
2import plotly.express as px
3import plotly.io as pio
4pio.renderers.default = 'notebook'
Plotly Express er en del av Plotly. Det er vanlig å referere til modulen som px, på samme måte som det er vanlig å referere til Pandas som pd. De to siste linjene, 3 og 4 trenges i visse situasjoner for at plottene skal vises. Vi skal nå gå gjennom enkle diagrammer som vi kan generere med Plotly
Stolpediagram#
I forrige kapittel så vi på et eksempel av data om masteroppgaver ved OsloMet. Vi starter ved å opprette dataframen fra csv-filen i data-katalogen, og ber den vise oss hvilke kolonner datasettet består av:
df_oda = pd.read_csv('data/oda-master-thesis.csv', sep = ',')
df_oda.columns
Index(['Title', 'Identifier', 'Creators', 'Supervisors', 'Lang', 'Subjects',
'SubjectsVDP', 'Date', 'Institute', 'FacultyShort', 'FacultyLong',
'InstituteShort', 'InstituteLong', 'MasterProg', 'LangNorm'],
dtype='object')
For helt grunnleggende statistikk er det viktig å kunne telle antall forekomster av verdier i diverse kolonner.
Nedenfor bruker vi funksjonen .value_counts() til å telle antall oppgaver hvert institutt har i datasettet.
1df_oda['InstituteShort'].value_counts()
SHA 521
SF 499
HHS 478
GFU 275
YLU 263
EST 185
AV 167
IT 133
ABI 129
BLU 102
PD 93
BE 84
FYS 78
IST 70
NVH 42
JM 23
EO 7
Name: InstituteShort, dtype: int64
Vårt første plott blir et stolpediagram med disse fordelingen av språk på tvers av alle oppavene. For å bruke dette i Plotly må vi først gjør om resultatet av tellingen (.value_counts()) til en dataframe.
1df_temp = df_oda['LangNorm'].value_counts().to_frame()
2df_temp
| LangNorm | |
|---|---|
| nor | 2443 |
| eng | 695 |
| oth | 11 |
I cellen nedenfor gjør vi om den gamle rad-indeksen (kolonnen med språkene) til en vanlig kolonne og gir deretter kolonnene nye navn. Denne eksisterer nå som en ny dataframe.
1df_temp.reset_index(inplace = True)
2
3col_map = {
4 'index' : 'Språk',
5 'LangNorm' : 'Antall'
6}
7
8df_temp.rename(columns = col_map, inplace = True)
9df_temp
| Språk | Antall | |
|---|---|---|
| 0 | nor | 2443 |
| 1 | eng | 695 |
| 2 | oth | 11 |
Den resulterende dataframen, df_temp, kan nå brukes for å lage stolpediagrammet. I cellen nedenfor opprettes en objektvariabel fig som tilordnes resultatet av .bar()-funskjonen fra Plotly Express. fig representerer et objekt av typen Figure, som har mange funksjoner (også kalt metoder). Metoden show() som brukes til slutt er den som driver mekanismen som viser diagrammet i tegneområdet. Metoden .bar() som produserer og returnerer fig-objektet kan ta mange parametre. De viktigste listes nedenfor:
* dataframen i eksempelet: `df_temp`
* tittelen gitt til horisontalaksen (x) i eksempelet: 'Språk'
* tittelen gitt til vertikalaksen (y) i eksempelet: 'Antall'
1import plotly.io as pio
2pio.renderers.default = 'notebook'
3fig = px.bar(
4 df_temp,
5 x = 'Språk',
6 y = 'Antall'
7)
8
9fig.show()
Dette resulteter i stolpediagrammet på figuren over.
✍️ Oppgave: Gjør det samme som over i din egen notebook. Bytt gjerne ut “Språk” med en annen verdi som du tenker det kan være hensiktsmessig å telle.
Hvis vi lar musepekeren hvile til høyre over diagramet, vises en knapperad som lar oss manipulere diagramet (figuren nedenfor). Her kan vi lagre diagrammet som et bildefil i PNG-formatet, zoome inn og ut, osv.

Endre tittel og farger#
Vi kan legge til en tittel på diagrammet ved å bruke title-parameteren til .bar()-funskjonen (Det samme kan vi gjøre hos de andre av Plotly sine graf-funksjoner).
Det er stor fleksibitet i hvilke farger som kan brukes. Dette oppgis med color_discrete_sequence-parameteren. Det finne flere ferdige fargekombinasjoner, f.eks. px.colors.qualitative.T10. Noen er vist på figuren .
–> Se Plotly dokumentasjon for en fullstendig liste.

Alternativt kan vi bruke fargenavn fra CSS, AliceBlue, AntiqueWhite, osv. Eller heksadesimalkoder, f.eks. #00FFFF.
Se f.eks. W3Schools for en oversikt over koder.
Flere, “grunnleggende” farger kan angis ved navn.
1colours = ['green']
2
3colours
['green']
Når vi legger inn koder slik, selv om det bare er ett element som skal fargelegges (som ovenfor), må disse legges inn i en Python-liste. Hvis stolpene skal være grønne og vi har tre stolper kan vi skrive ['green', 'green', 'green'].
1colours = ['green', 'green', 'green']
2colours
['green', 'green', 'green']
Men vi kan også gjøre dette på en annen måte om vi skal ha samme farge for alle kolonner. Legg merke til cellen nedenfor. Her brukes *-operatoren til å mangfoldiggjøre listen ['green'] et gitt antall ganger (her 3).
1['green'] * 3
['green', 'green', 'green']
Dette gir oss muligheten til enkelt å bruke len()-funksjon (dataframens lengde) for å fargelegge alle rader i dataframen likt.
1colours = ['green']
2colours * len(df_temp)
['green', 'green', 'green']
Og slik brukes det i selve plottet:
1fig = px.bar(
2 df_temp,
3 x = 'Språk',
4 y = 'Antall',
5 color_discrete_sequence = ['green'] * len(df_temp),
6 title = 'Fordeling av OsloMet masteroppgavene etter språk'
7)
8
9fig.show()
Kakediagram#
Fordeling av språk kan også vises som et kakediagram ved å bruke .pie()-funksjonen.
Dataframen som brukes er den samme som ovenfor. Istedenfor x og y brukes parameteren names for kategoriene og values for fordelingen.
Her ønsker vi i tillegg vise språkenes fulle navn (Dette kan også gjøres i stolpediagrammet, bare prøv!). Til dette anvender vi dict’en value_map.
1df_temp = df_oda['LangNorm'].value_counts().to_frame()
2df_oda
3df_temp.reset_index(inplace = True)
4
5col_map = {
6 'index' : 'Språk',
7 'LangNorm' : 'Antall'
8}
9
10df_temp.rename(columns = col_map, inplace = True)
11
12value_map = {
13 'nor' : 'Norsk',
14 'eng' : 'Engelsk',
15 'oth' : 'Annet'
16}
17
18df_temp['Språk'] = df_temp['Språk'].map(value_map)
19
20df_temp
| Språk | Antall | |
|---|---|---|
| 0 | Norsk | 2443 |
| 1 | Engelsk | 695 |
| 2 | Annet | 11 |
Nedenfor ser vi også bruk av parametrene til .update_layout()-metoden, som kan brukes for å midtstille overskriften (title_x) og endre skriftstørrelse til overskriften (title_font_size).
1fig = px.pie(
2 df_temp,
3 names = 'Språk',
4 values = 'Antall'
5)
6
7fig.update_layout(
8 showlegend = False
9)
10
11fig.update_traces(
12 textposition = 'outside',
13 textinfo = 'percent+label'
14)
15
16fig.show()
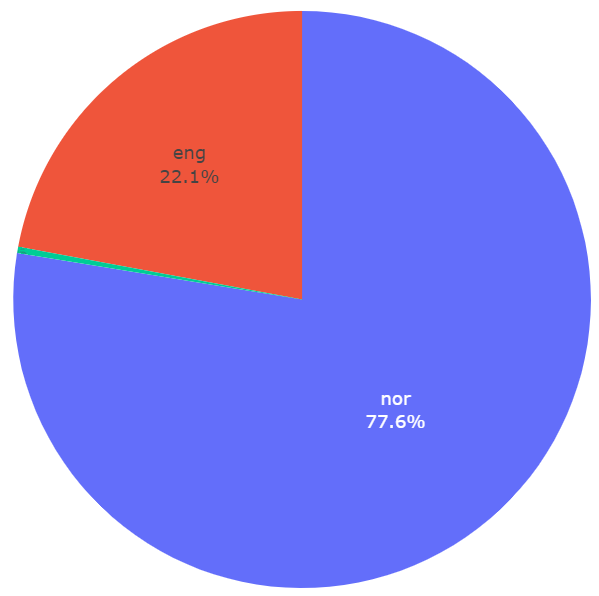
Resultatet ser vi på figuren over.
Hvis musepekeren hviler over et kakestykke vises ekstra opplysninger om kakestykke: Som vi ser på figuren nedenfor, kategorien eng og absoluttallet 2443. Prøv også å flytte markøren over diagrammet over.
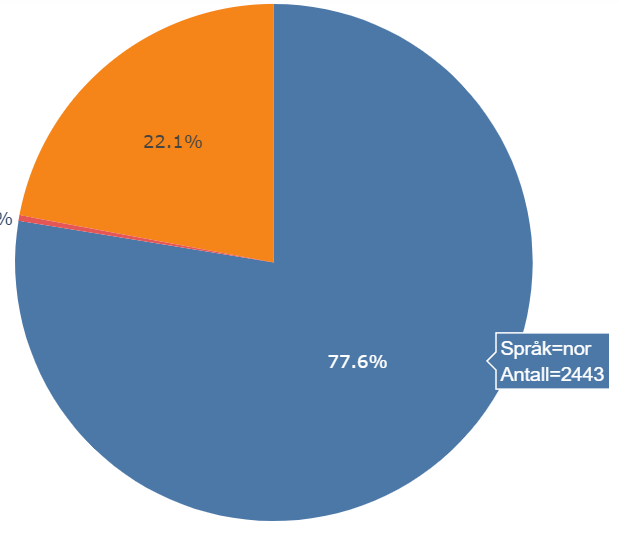
Vi kan legge inn opplysninger i selve kaken ved å bruke .update_traces()-metoden (se linje 11 i koden over). Vi har fjernet noen av parametrene fra før for å spare plass. Hvis kategoriene legges i kaken kan vi vurdere å fjerne forklaringen til diagrammet (eng. “legend”). Dette gjøres ved å sette parameteren showlegend til False.
Merk at annet språk (oth) vises så vidt ikke på figuren nedenfor (en stripe grønt), grunnet størrelsen. Fargene som brukes her er standardfargene til Plotly.
Gruppert stolpediagram#
For å sammenligne språkfordelingen på fakultetene, bruker vi .groupby()-metoden i Pandas. For å visualisere slike analyser kan vi bruke grupperte eller stablete stolpediagram.
I cellen nedenfor grupperer vi språkkodene etter fakultet. Settingen normalize = True medfører at tallene vises som relativtall. Resultatet gjøres om til en dataframe.
1df_temp = df_oda.groupby('FacultyShort')['LangNorm'].value_counts(normalize = True).to_frame()
2
3df_temp
| LangNorm | ||
|---|---|---|
| FacultyShort | LangNorm | |
| HV | nor | 0.829448 |
| eng | 0.166871 | |
| oth | 0.003681 | |
| LUI | nor | 0.887324 |
| eng | 0.112676 | |
| SAM | nor | 0.754650 |
| eng | 0.240035 | |
| oth | 0.005314 | |
| TKD | nor | 0.575758 |
| eng | 0.420202 | |
| oth | 0.004040 |
Som du ser, har vi her en multiindex, en indeks med flere nivåer (her: to). Legg også merke til at value_counts()-funksjonen produserer en tallkolonne (på multiindeksens øverste nivå), som heter det samme som kolonnen på annet nivå, noe som må “brytes opp”. Dette gjør vi ved å endre førstenivåkolonnens navn til Prosent:
1col_map = {
2 'LangNorm' : 'Prosent'
3}
4df_temp.rename(columns = col_map, inplace = True)
5
6df_temp
| Prosent | ||
|---|---|---|
| FacultyShort | LangNorm | |
| HV | nor | 0.829448 |
| eng | 0.166871 | |
| oth | 0.003681 | |
| LUI | nor | 0.887324 |
| eng | 0.112676 | |
| SAM | nor | 0.754650 |
| eng | 0.240035 | |
| oth | 0.005314 | |
| TKD | nor | 0.575758 |
| eng | 0.420202 | |
| oth | 0.004040 |
rename()-funksjonen forholder seg til det øverste nivået når det lager Prosent-kolonnen.
Nedenfor prosentuerer vi denne i praksis, simpelthen ved å gange verdiene med 100:
1df_temp['Prosent'] = df_temp['Prosent'] * 100
2
3df_temp
| Prosent | ||
|---|---|---|
| FacultyShort | LangNorm | |
| HV | nor | 82.944785 |
| eng | 16.687117 | |
| oth | 0.368098 | |
| LUI | nor | 88.732394 |
| eng | 11.267606 | |
| SAM | nor | 75.465013 |
| eng | 24.003543 | |
| oth | 0.531444 | |
| TKD | nor | 57.575758 |
| eng | 42.020202 | |
| oth | 0.404040 |
Tilbake til multiindeksen:
1df_temp.index
MultiIndex([( 'HV', 'nor'),
( 'HV', 'eng'),
( 'HV', 'oth'),
('LUI', 'nor'),
('LUI', 'eng'),
('SAM', 'nor'),
('SAM', 'eng'),
('SAM', 'oth'),
('TKD', 'nor'),
('TKD', 'eng'),
('TKD', 'oth')],
names=['FacultyShort', 'LangNorm'])
I følgende celle brukes reset_index for å gjøre om multiindeksen til vanlige kolonner, og innføre et default-tallindeks.
1df_temp.reset_index(inplace = True)
2df_temp
| FacultyShort | LangNorm | Prosent | |
|---|---|---|---|
| 0 | HV | nor | 82.944785 |
| 1 | HV | eng | 16.687117 |
| 2 | HV | oth | 0.368098 |
| 3 | LUI | nor | 88.732394 |
| 4 | LUI | eng | 11.267606 |
| 5 | SAM | nor | 75.465013 |
| 6 | SAM | eng | 24.003543 |
| 7 | SAM | oth | 0.531444 |
| 8 | TKD | nor | 57.575758 |
| 9 | TKD | eng | 42.020202 |
| 10 | TKD | oth | 0.404040 |
Til slutt omdøper vi kolonnen FacultyShort til Fakultet og kolonnen LangNorm til Språk. Dette gjør det enklere å holde styr på hva de ulike kolonnene består av.
1col_map = {
2 'FacultyShort' : 'Fakultet',
3 'LangNorm' : 'Språk'
4}
5
6df_temp.rename(columns = col_map, inplace = True)
7
8df_temp
| Fakultet | Språk | Prosent | |
|---|---|---|---|
| 0 | HV | nor | 82.944785 |
| 1 | HV | eng | 16.687117 |
| 2 | HV | oth | 0.368098 |
| 3 | LUI | nor | 88.732394 |
| 4 | LUI | eng | 11.267606 |
| 5 | SAM | nor | 75.465013 |
| 6 | SAM | eng | 24.003543 |
| 7 | SAM | oth | 0.531444 |
| 8 | TKD | nor | 57.575758 |
| 9 | TKD | eng | 42.020202 |
| 10 | TKD | oth | 0.404040 |
For å lage en gruppert stolpediagram må vi legge til noen parameter til .bar()-funskjonen vi brukte tidligere. Vi må legge til barmode-parameteren med group som verdi (linje 6). Selve gruppene legges inn som x-akse. Kategoriene som grupperer, her språk, legges inn i color-parameteren.
1fig = px.bar(
2 df_temp,
3 x = 'Fakultet',
4 y = 'Prosent',
5 color = 'Språk',
6 barmode = 'group',
7 color_discrete_sequence = px.colors.qualitative.T10,
8 title = 'Språk av OsloMet masteroppgavene etter fakultet',
9)
10
11fig.show()
✍️ Oppgave: Gjør det samme som beskrevet over, men forsøk å gruppere etter institutt og ikke fakultet.
Stablet stolpediagram#
Den eneste endring som er nødvendig for å endre fra gruppert til stablet stolpediagram er å endre verdien av barmode-parameteret til relative (linje 6).
Hvis du klikker på en kategori i forklaringen, fjernes katagorien fra visningen. Klikk en gang til for å hente den tilbake. For eksempel, hvis vi kun vil vise andelen som er på engelsk kan vi klikke på nor og oth.
1fig = px.bar(
2 df_temp,
3 x = 'Fakultet',
4 y = 'Prosent',
5 color = 'Språk',
6 barmode = 'relative',
7 color_discrete_sequence = ['green', 'yellow', 'red'], #px.colors.qualitative.T10,
8 title = 'Språk av OsloMet masteroppgavene etter fakultet',
9)
10
11fig.show()
Linjediagram#
Linjediagrammer er ofte brukt med tidsdata, slik at X-aksen representerer tiden. Hvordan har fordelingen av språk endret seg over tid? Som før lager vi en dataframe med dataene vi ønsker å bruke i visualiseringen. Mye av dette ligner det forrige eksemplet, men her grupperer vi på dato heller enn på fakultet ( se linje 1 i cellen nedenfor.).
1df_temp = df_oda.groupby('Date')['LangNorm'].\
2value_counts(normalize = True).to_frame()
3
4col_map = {
5 'LangNorm' : 'Prosent'
6}
7df_temp.rename(columns = col_map, inplace = True)
8df_temp.reset_index(inplace = True)
9df_temp['Prosent'] = df_temp['Prosent'] * 100
10
11df_temp.head()
| Date | LangNorm | Prosent | |
|---|---|---|---|
| 0 | 2003 | nor | 100.000000 |
| 1 | 2005 | eng | 90.909091 |
| 2 | 2005 | nor | 9.090909 |
| 3 | 2006 | eng | 75.000000 |
| 4 | 2006 | nor | 25.000000 |
For at data skal vises riktig, må verdiene i Date-kolonnen (som vi ønsker å omdøpe til År) endres fra tekststrenger til datoer. Dette gjøre vha .to_datatime()-funksjonen fra Pandas (linje 7). Datoer kan skrives på mange ulike måter. Vi kan bruke format-parameteren til å angi formatet. Formatet %Y betyr at kun årstallet vises.
1col_map = {
2 'Date' : 'År',
3 'LangNorm' : 'Språk'
4}
5df_temp.rename(columns = col_map, inplace = True)
6
7df_temp['År'] = pd.to_datetime(df_temp['År'], format = '%Y')
8
9df_temp.head()
| År | Språk | Prosent | |
|---|---|---|---|
| 0 | 2003-01-01 | nor | 100.000000 |
| 1 | 2005-01-01 | eng | 90.909091 |
| 2 | 2005-01-01 | nor | 9.090909 |
| 3 | 2006-01-01 | eng | 75.000000 |
| 4 | 2006-01-01 | nor | 25.000000 |
⚠️ Merk! Legg merke til at Pandas har lagt 01-01 til året for å gjøre det om til en dato.
For å vise et linjediagram bruker vi line()-funksjon i Plotly. Bruk av color-parameteren gir oss en linje for hver kategori (linje 4). markers-parameter bestemmer om punktene skal markeres på linjen (linje 5).
1fig = px.line(df_temp,
2 x= 'År',
3 y= 'Prosent',
4 color = 'Språk', # Hva er det fargene skiller på
5 markers = True
6)
7
8fig.show()
Resultatet ser du på plottet over. Legg merke til at vi mangler data for noen tidspunkter. Dette er et eksempel på at når vi jobber med å få frem mønstre i data vil vi også oppdage noe det kan være interessantå dykke dypere ned i.
Hva skjedde i 2005? Her bør vi se i grunnlagsdataene. Vi lager et filter for å kun se rader fra 2005 (linje 1). Vi avgrenser visningen til kolonnene for tittel, årstall, språk og institutt (linje 3-8).
1filter1 = df_oda['Date'] == 2005
2
3cols = [
4 'Title',
5 'Date',
6 'Lang',
7 'InstituteLong'
8]
9
10df_oda[filter1][cols]
| Title | Date | Lang | InstituteLong | |
|---|---|---|---|---|
| 2095 | Langtidssosialhjelpsmottakere : veien til sosi... | 2005 | nb | Institutt for sosialfag |
| 2664 | Evaluation of file access control implementations | 2005 | en | Institutt for informasjonsteknologi |
| 2677 | Predicting TCP congestion through active and p... | 2005 | en | Institutt for informasjonsteknologi |
| 2679 | High speed network sampling | 2005 | en | Institutt for informasjonsteknologi |
| 2687 | Administration of remote computer networks | 2005 | en | Institutt for informasjonsteknologi |
| 2707 | Retrivability of data in ad-hoc backup | 2005 | en | Institutt for informasjonsteknologi |
| 2710 | Virtual user simulation | 2005 | en | Institutt for informasjonsteknologi |
| 2716 | User survey of practices using cfengine | 2005 | en | Institutt for informasjonsteknologi |
| 2718 | Passive traffic characterization and analysis ... | 2005 | en | Institutt for informasjonsteknologi |
| 2754 | Traffic classification with passive measurement | 2005 | en | Institutt for informasjonsteknologi |
| 2763 | Comparison of NFS, Samba and AFS | 2005 | en | Institutt for informasjonsteknologi |
Over ser vi at vi har kun 11 oppgaver fra 2005. 10 var skrevet på engelsk og alle var skrevet på instituttet for informasjonsteknologi. Hva dette skyldes kan ikke dataene vi har alene svare på.
Spredningsdiagram#
Her bruker vi data fra statistikk for norske folkebibliotek. Vi er interessert i å vise forholdet mellom folketall og besøkstall. Er det slik at bibliotek i kommuner med høyere folketall har mer besøk?
1df_bib = pd.read_csv('data/folkebibl-2020-kommuner.csv', sep = ',')
2df_bib.columns, df_bib.shape
(Index(['Antall kommuner i fylket', 'Fylkesnr.', 'Kommunenr.', 'Kommune',
'0-14 år per 1.1.2020', '15 år og eldre per 1.1.2020',
'Totalt per 1.1.2020', 'Besøk totalt', 'Besøk i betjent åpningstid',
'Arrangement skoler - totalt',
...
'Kombinasjons-bibliotek med annen skole/\r\ninstitusjon',
'Utlånssteder utenfor biblioteket', 'Leseplasser ved hoved-biblioteket',
'Leseplasser ved avdelingene', 'Nye lokaler', 'Antall mobile enheter',
'Antall stoppesteder for mobile enheter',
'Regnskap, lønn og sosiale utgifter ', 'Regnskap, kjøp av medier',
' Regnskap lønn- og medieutgifter totalt '],
dtype='object', length=212),
(355, 212))
Over viser vi (et utdrag av) kolonnenavnene og størrelsen på datatabellen. CSV-filen med bibliotekstatistikk har over 200 kolonner med statistikk.
Vi ser så nærmere på hva som er i dette datasettet ved å be den vise frem filen som en dataframe:
1df_bib
| Antall kommuner i fylket | Fylkesnr. | Kommunenr. | Kommune | 0-14 år per 1.1.2020 | 15 år og eldre per 1.1.2020 | Totalt per 1.1.2020 | Besøk totalt | Besøk i betjent åpningstid | Arrangement skoler - totalt | ... | Kombinasjons-bibliotek med annen skole/\r\ninstitusjon | Utlånssteder utenfor biblioteket | Leseplasser ved hoved-biblioteket | Leseplasser ved avdelingene | Nye lokaler | Antall mobile enheter | Antall stoppesteder for mobile enheter | Regnskap, lønn og sosiale utgifter | Regnskap, kjøp av medier | Regnskap lønn- og medieutgifter totalt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 30.0 | 3024.0 | Bærum | 24 806 | 102 925 | 127 731 | 307 528 | 307 145 | 46.0 | ... | 0.0 | 2.0 | 209 | 380 | Nei | 0.0 | 0.0 | 32 743 318 | 3 551 352 | 36 294 670 |
| 1 | NaN | 30.0 | 3005.0 | Drammen | 17 439 | 83 947 | 101 386 | 275 962 | NaN | 31.0 | ... | 0.0 | 0.0 | NaN | NaN | Nei | 0.0 | 0.0 | 20 736 256 | 1 543 435 | 22 279 691 |
| 2 | NaN | 30.0 | 3025.0 | Asker | 18 067 | 76 374 | 94 441 | 268 127 | 266 115 | 183.0 | ... | NaN | 1.0 | 238 | 122 | Nei | NaN | NaN | 23 056 421 | 2 375 880 | 25 432 301 |
| 3 | NaN | 30.0 | 3030.0 | Lillestrøm | 15 999 | 69 984 | 85 983 | 171 063 | 160 234 | 55.0 | ... | 0.0 | 0.0 | 200 | 168 | Nei | 0.0 | 0.0 | 16 607 879 | 1 789 507 | 18 397 386 |
| 4 | NaN | 30.0 | 3004.0 | Fredrikstad | 13 566 | 68 819 | 82 385 | 175 412 | 175 412 | 29.0 | ... | 1.0 | NaN | 136 | 72 | Ja | 0.0 | 0.0 | 17 111 866 | 1 459 072 | 18 570 938 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 350 | NaN | 54.0 | 5415.0 | Loabák - Lavangen | 180 | 854 | 1 034 | NaN | NaN | 1.0 | ... | 0.0 | 0.0 | 10 | 0 | Nei | 0.0 | 0.0 | 339 325 | 38 595 | 377 920 |
| 351 | NaN | 54.0 | 5433.0 | Hasvik | 148 | 857 | 1 005 | 740 | 548 | 0.0 | ... | NaN | NaN | 8 | NaN | Nei | NaN | NaN | 247 509 | 60 000 | 307 509 |
| 352 | NaN | 54.0 | 5440.0 | Berlevåg | 106 | 851 | 957 | 794 | 794 | 0.0 | ... | 1.0 | 0.0 | 10 | 0 | Nei | 0.0 | 0.0 | 396 268 | 32 051 | 428 319 |
| 353 | NaN | 54.0 | 5442.0 | Unjárga - Nesseby | 129 | 797 | 926 | 808 | 808 | 2.0 | ... | NaN | NaN | 16 | NaN | Nei | 1.0 | 82.0 | 584 066 | 53 000 | 637 066 |
| 354 | NaN | 54.0 | 5432.0 | Loppa | 85 | 803 | 888 | 1 007 | NaN | NaN | ... | NaN | 3.0 | 10 | NaN | Nei | NaN | NaN | 750 000 | 50 000 | 800 000 |
355 rows × 212 columns
Her er vi interessert i kolonnen Besøk totalt og Totalt per 1.1.2020. Imidlertid kan det virke som det som står i kolonnen “Besøk totalt” er tekst. En indikasjon på dette er at det er et mellomrom mellom de tre første tallene og de tre siste.
Kolonnen Totalt per 1.1.2020 må vaskes før vi kan bruke den videre.
Vi vasker direkte i notebooken (men dette kan også gjøres i OpenRefine). Vi fjerner først mellomrom fra tallene (eks. 307 528 til 307528). Nå som mellomrom er borte kan vi endre datatype i kolonnen til å være tall og ikke tekst. Til dette bruker vi i begge cellene, ovenfor linje 8 og nedenfor linje 5, Pandas-funksjonen to_numeric. Vi omdøper også Totalt per 1.1.2020 til Folketall:
1# definer funksjonen vi skal anvende
2def vaskMellomRom(verdi):
3 return verdi.replace(' ', '')
4
5#fjern mellomrom i tall. (typisk dataproblem)
6df_bib['Totalt per 1.1.2020'] = df_bib['Totalt per 1.1.2020'].apply(vaskMellomRom)
7
8# Go kolonne nytt navn
9col_map = {
10 'Totalt per 1.1.2020' : 'Folketall'
11}
12df_bib.rename(columns = col_map, inplace = True)
13
14# Endre datatype
15df_bib['Folketall'] = pd.to_numeric(df_bib['Folketall'])
Her brukte vi metoden Series.apply(), som anvender en funksjon (her vaskMellomRom) på hver av innførslene. Se på syntaksen på linje 6: apply() bruker funksjonens navn alene (uten parentes og argument). Bak kulissene brukes hver av innførslene, etter tur, som argument til funksjonen, og vasket verdi returneres.
✍️ Oppgave: Gjør det samme som over i din egen notebook. Sjekk så df_bib for at endringene er blitt gjort og for å få en oversikt over hvordan dataframen nå ser ut.
En annen måte å fjerne mellomrom på er gjort med den andre kolonnen i cellen under. Her skjer mer bak kulissene, men produserer samme resultat; mellomrom fjernes.
1df_bib['Besøk totalt'].fillna('', inplace = True)
2
3df_bib['Besøk totalt'] = df_bib['Besøk totalt'].apply(lambda x: x.replace(' ', ''))
4
5df_bib['Besøk totalt'] = pd.to_numeric(df_bib['Besøk totalt'])
Utgangspunktet for diagrammet kodes i cellen nedenfor. På linje 3 oppretter vi en ny kolonne som inneholder besøk per person. Vi viser data for de ti bibliotek med høyest besøkstall.
1cols = ['Kommune', 'Folketall', 'Besøk totalt', 'Besøk per person']
2
3df_bib['Besøk per person'] = df_bib['Besøk totalt'] / df_bib['Folketall']
4
5df_bib.sort_values('Besøk totalt', ascending = False)[cols].head(10)
| Kommune | Folketall | Besøk totalt | Besøk per person | |
|---|---|---|---|---|
| 51 | Oslo | 693494 | 2441381.0 | 3.520407 |
| 145 | Stavanger | 143574 | 1039369.0 | 7.239256 |
| 168 | Bergen | 283929 | 733405.0 | 2.583058 |
| 237 | Trondheim | 205163 | 669357.0 | 3.262562 |
| 120 | Kristiansand | 111633 | 314976.0 | 2.821531 |
| 0 | Bærum | 127731 | 307528.0 | 2.407622 |
| 316 | Tromsø | 76974 | 300944.0 | 3.909684 |
| 1 | Drammen | 101386 | 275962.0 | 2.721895 |
| 2 | Asker | 94441 | 268127.0 | 2.839095 |
| 275 | Bodø | 52357 | 253000.0 | 4.832210 |
Nedenfor bruker vi scatter-funksjonen fra Plotly for å lage spredningsdiagrammet. Igjen, parametre for tittel osv. er utelatt for å fremheve de viktigste parametrene. Vi bruker hover_name-parameteren for å legge ekstra data til boksen som vises når vi sette musepekeren over et punkt på diagrammet.
1#Vil vise sammenheng i småsteder
2
3fig = px.scatter(
4 df_bib,
5 x = 'Folketall',
6 y = 'Besøk totalt',
7 hover_name = 'Kommune'
8)
9
10fig.show()
Ovenfor vises resultatet. De alle fleste bibliotek er klumpet nederst til venstre i diagrammet.
Vi kan bruke et filter for å fjerne de fire største komunnene. På linje 2 i kodecellen nedenfor oppretter vi en liste med de kommunene som vi ikke vil ha. På linje 4 bruker vi .isin()-metoden for å lage et filter som kun tar med disse fire kommune. Når vi bruker filteret på dataframe (linje 7), setter vi ~-tegnet foran for å si at vi vil ha alt som ikke matcher filteret.
1#Vil vise sammenheng i småsteder
2fjern = ['Oslo', 'Bergen', 'Trondheim', 'Stavanger']
3
4filter1 = df_bib['Kommune'].isin(fjern)
5
6fig = px.scatter(
7 df_bib[~filter1],
8 x = 'Folketall',
9 y = 'Besøk totalt',
10 hover_name = 'Kommune'
11)
12
13fig.show()
Resultatet ser du ovenfor.
Boksplot#
Blir bibliotek i større kommuner oftere besøkt (per innbygger) enn bibliotek i mindre kommuner? Eller er det kanskje omvendt? Èn måte å finne ut av det, er å dele kommunene i kvantiler: Altså et antall like store grupper bibliotek, i stigende antall innbyggere, og se gruppenes fordelinger av relative besøkstall (herunder kalt besøksrate) opp i mot hverandre. Linje 1 nedenfor deler vi kommunene i 4 folketallskvantiler, slik at de minste kommunene havner i det nederste kvantilet (0), de litt større i neste kvantilet (1), osv. Linje 2 legger til en kolonne i data-framen (kalt kvantil) hvor hver kommune får “sitt” kvantil (0, 1, 2 eller 3) tilordnet.
1kvantiler = pd.qcut(df_bib['Folketall'], 4, labels=False)
2df_bib = df_bib.assign(kvantil=kvantiler.values)
Nå er vi klare til å tegne boksplottet for hvert kvantil. Boksplot er en god måte å vise relative tendenser på, samt å isolere “outliers”.
1fig = px.box(
2 df_bib,
3 x = 'kvantil',
4 y = 'Besøk per person',
5 hover_name = 'Kommune',
6 color='kvantil',
7)
8fig.update_traces(quartilemethod="linear") # or "inclusive", or "linear" by default
9
10fig.show()
Hold musepekeren over boksene. Et nøye blikk på boksene kan tyde på en svak tendens til at større kommuner har flere besøk per innbygger. Men er dette en virkelig trend? i statistikkspråk: Er den signifikant? eller med andre ord: Hva er sannsynligheten for at utviklingen vi ser er tilfeldig? Boksene vi ser tyder på at fordelingen er meget skjev. Altså: besøk-ratene i alle kvantilene klumper seg ikke likt til høyre og til venstre for et gjennomsnitt.
Hvis vi vil undersøke disse aggregerte mønstrene nærmere med utgangspunkt i statistiske analyser kan vi gjøre følgende beskrevet under:
Cellen nedenfor genererer en tetthetfordelingsplot, et slags glattet histogram, for hver av kvantilene. Her bruker vi figure_factory-modulen til Plotly.
1import plotly.figure_factory as ff
2
3
4kv0 = list(df_bib[df_bib['kvantil']==0]['Besøk per person'].fillna(0))
5kv1 = list(df_bib[df_bib['kvantil']==1]['Besøk per person'].fillna(0))
6kv2 = list(df_bib[df_bib['kvantil']==2]['Besøk per person'].fillna(0))
7kv3 = list(df_bib[df_bib['kvantil']==3]['Besøk per person'].fillna(0))
8
9hist_data = [kv0, kv1, kv2, kv3]
10
11group_labels = ['kv0', 'kv1', 'kv2', 'kv3']
12colors = ['green', 'blue', 'red', 'black']
13
14# Create distplot with curve_type set to 'normal'
15fig = ff.create_distplot(hist_data, group_labels, show_hist=False, colors=colors)
16
17# Add title
18fig.update_layout(title_text='Besøksrate fire kvantiler')
19fig.show()
Ved å se på figuren over er det lett å miste håpet om at folketallet er forklarende til forskjell i besøksraten. Det er også lett å se at hovedtyngdene av kvantilene har en tilnærmet normal fordeling, hvor de lange halene representerer relativt få verdier. Da vi også har relativt mange datapunkter, drister vi oss til å kjøre en T-test mellom kv0 og kv3, som er kvantilene hvis gjennomsnitt ligger lengst unna hverandre i plottet.
En T-test tester om to datasett “kommer fra” den samme fordelingen (hypotesen h0) eller ikke (h1). Vi avviser stort sett h0 (default-hypotesen) hvis p-verdien er mindre enn 0,05.
1from scipy.stats import ttest_ind
2kv0 = list(df_bib[df_bib['kvantil']==0]['Besøk per person'].fillna(0))
3kv3 = list(df_bib[df_bib['kvantil']==3]['Besøk per person'].fillna(0))
4ttest_ind(kv0, kv3, equal_var=False)
Ttest_indResult(statistic=-0.5339022621071996, pvalue=0.5944288128684567)
Med en så stor p-verdi er vi langt fra å kunne avvise h0, dvs foreslå at besøksraten har noe med folketallet å gjøre.
Du har nå fått en smakebit på hvordan undersøke sammenheng mellom variabler i aggregerte mønstre nærmere. Merk at vi ikke skal gå nærmere inn på slike statistiske analyser i dette kapitlet.
Ordsky#
Det siste vi skal ta for oss er en metode som gir deg en alternativ oversikt til en lang liste over ordfrekvenser. Her er istedet størrelsen på ordet en indikasjon på forekomst, mens andre variabler som farge og plassering er arbitrære.
For å generere en ordky bruker vi wordcloud-modulen. For å installere moduelen åpner vi Anaconda Prompt i Anaconda. Skriv inn kommandoen pip install wordcloud.
I cellen nedenfor importeres modulen og en del variabler derfra. Deretter lager vi teksten som skal vises som et ordsky. Vi bruker emne-kolonnen fra ODA-datasettet om masteroppgavene. Først erstatter vi manglende verdier med blank (linje 2). Deretter oppretter vi en tom variabel, text (linje 4) som skal senere “fylles inn” med emneordene etter hvert som de hentes ut fra dataframens rader. For å avgrense til masteroppgaver skrevet ved ABI, lager vi et filter (linje 6). Vi går gjennom alle radene (oppgavene) som oppfyller filteret, og henter innholdet i Subjects-kolonnen (linje 9). Hvis en oppgave har flere emner, er emnene adskilt med |-tegnet. Vi bruker .replace()-metoden til å erstatte tegnet med et mellomrom (linje 8). På linje 11 sammenføyes emne(ne) bakerst i teksten. vi tilføyer en ekstra mellomrom for at siste ord i nåværende ikke sammenføyes direkte med førsteord i neste.
1from wordcloud import WordCloud, ImageColorGenerator, STOPWORDS
2df_oda['Subjects'].fillna('', inplace = True)
3
4text = ''
5
6filter1 = df_oda['InstituteShort'] == 'ABI'
7
8for idx, row in df_oda[filter1].iterrows():
9 subject = row['Subjects'].replace('|', ' ')
10
11 text += subject+ " "
Koden som lager ordskyet er vist under. I linjer 3 til 8 sette vi parameter til ordskyet. Teksten som vi har generert over brukes for å opprette ordskyen i linje 10.
1stopwords = set(STOPWORDS)
2
3wc= WordCloud(background_color="black",
4 random_state=1,
5 stopwords = stopwords,
6 max_words = 200,
7 width = 1500,
8 height = 1500)
9
10wc.generate(text)
<wordcloud.wordcloud.WordCloud at 0x7fc0bd091990>
Vi bruker Plotly for å vises bildet. Parametere i linjene 3-9 brukes for å fjerne aksene.
1fig = px.imshow(wc)
2
3fig.update_xaxes(
4 showticklabels=False
5)
6
7fig.update_yaxes(
8 showticklabels=False
9)
10
11fig.show()
Resultatet vises ovenfor.
Du har nå gått gjennom en innføring i det å visualisere aggregerte mønstre gjennom ulike grafer. Dette har vi gjort med utgangspunkt i datasett som allerede eksisterer som CSV-filer.